Track A: Viewer-Native
Agents operate 3D Slicer or QuPath using primitive viewer actions only. This isolates visual search, navigation, and evidence acquisition.
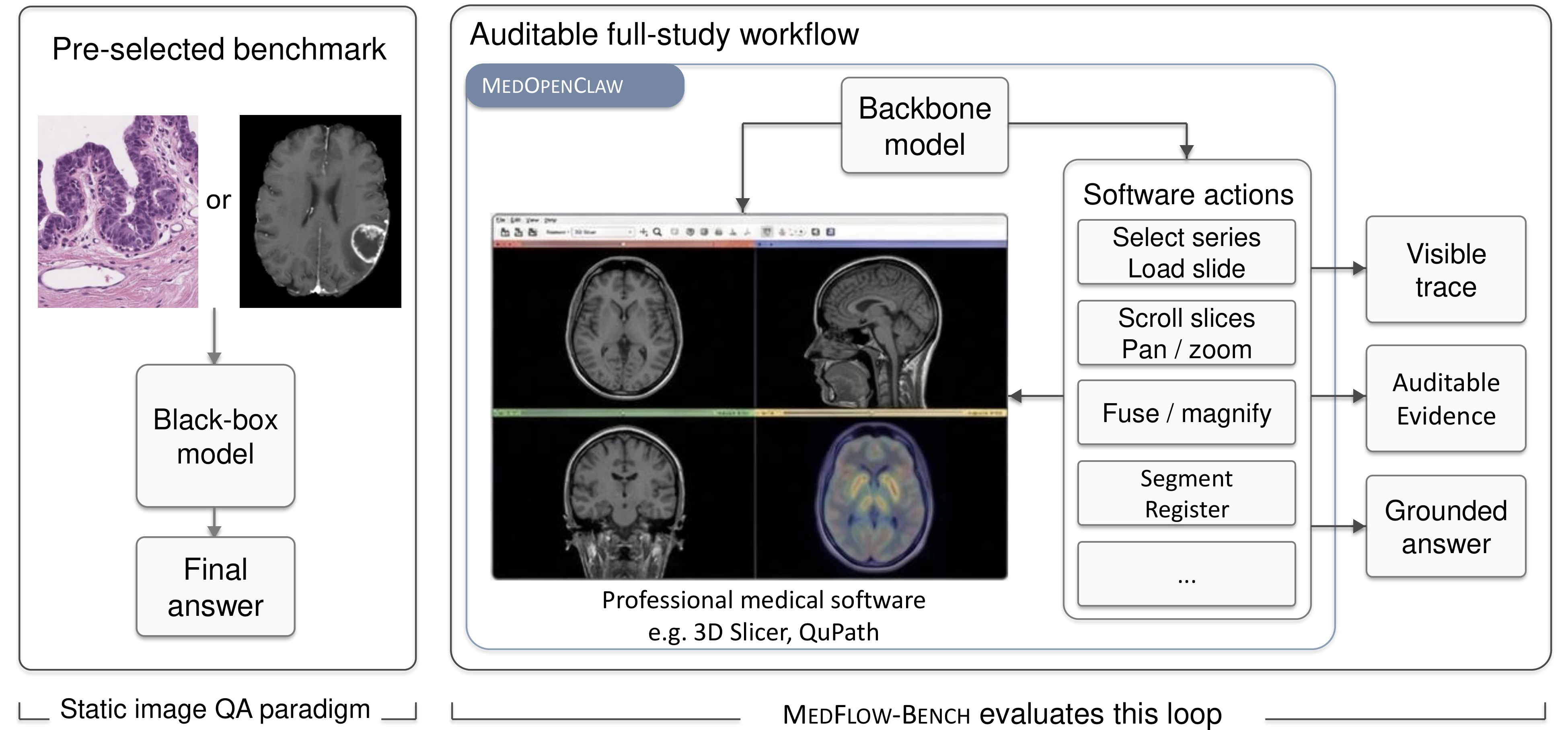
A full-study benchmark for radiology and pathology agents, with evidence-constrained scoring across viewer-native, advanced-operation, and runtime-agnostic tracks.
5
task families
1,459
benchmark-eligible cases
3
tracks
All tracks use identical cases, task formulations, and metrics. The split keeps primitive viewer control, advanced-operation use, and alternative full-study pipelines comparable without mixing them into one table.
Agents operate 3D Slicer or QuPath using primitive viewer actions only. This isolates visual search, navigation, and evidence acquisition.
Agents can invoke segmentation, registration, MONAI/VISTA3D, and related expert operations, then integrate outputs back into the workflow.
Methods may bypass MedOpenClaw while consuming raw cases and producing the same canonical answer and evidence schema.
MedFlowBench evaluates complete volumetric studies and whole-slide images, not pre-selected crops. Each module defines its own answer schema and evidence contract.
| Domain | Source | Cases | Input unit | Primary evidence contract |
|---|---|---|---|---|
| Radiology | LUMIERE | 139 | Baseline/follow-up brain MRI | RANO response category with lesion-state evidence fields. |
| Radiology | UCSF-PDGM | 495 | Multi-sequence brain MRI | Case-level tumor diagnosis with key-slice evidence and RAS localization. |
| Radiology | NSCLC PET/CT | 162 | Paired lung PET/CT study | Tumor location, T/N stage, histology, grade, and lesion evidence. |
| Pathology | BRACS | 113 | Breast whole-slide image | Seven-class slide diagnosis with QuPath ROI coordinate evidence. |
| Pathology | CAMELYON17 | 550 | Lymph-node whole-slide image | Tumor presence and metastasis category with coordinate evidence. |
This page explains MedFlowBench itself: tracks, modules, scoring, and failure cases. The live Track A/B/C ranking table lives on a dedicated leaderboard page.
Open leaderboardA model can guess a plausible label while failing to identify the slice, coordinate, region, or longitudinal evidence needed to audit that label.
Primary answer accuracy for the dataset-specific question or structured output.
Whether the returned evidence fields are correct under deterministic checks.
Credit only when the task answer and required evidence are both correct.
Whether the returned RAS point or WSI coordinate lands inside hidden masks or annotations.
These cases show failures in workflow intent, spatial grounding, state tracking, operation-output calibration, and procedural control.
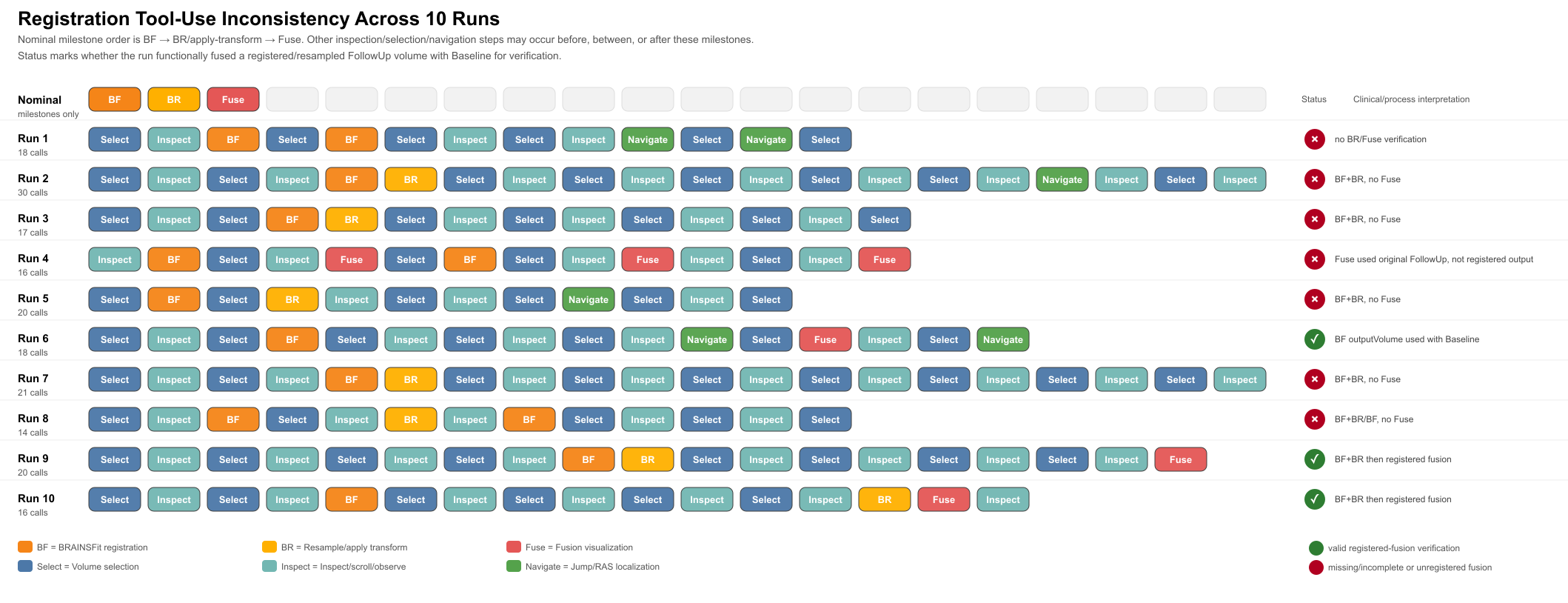
This figure is specifically about procedural control. It marks whether each run completes the expected registration sequence: BRAINSFit registration, resample/apply transform, then registered-fusion verification.
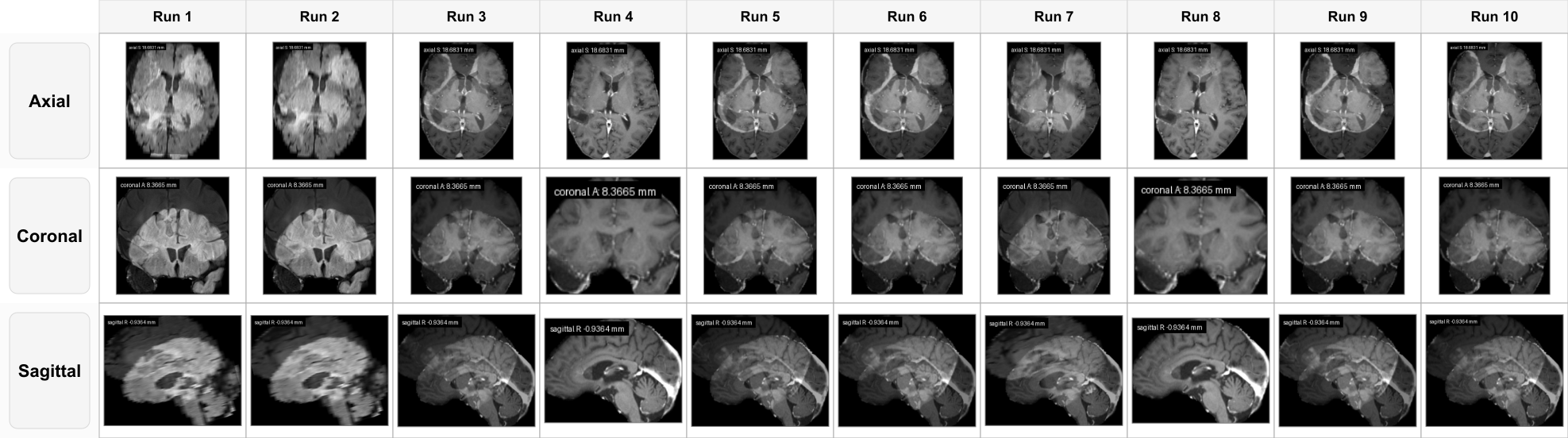
This figure shows the visual consequence of registration instability. Identical inputs lead to different final axial, coronal, and sagittal fusion views, so the evidence state itself is not stable.
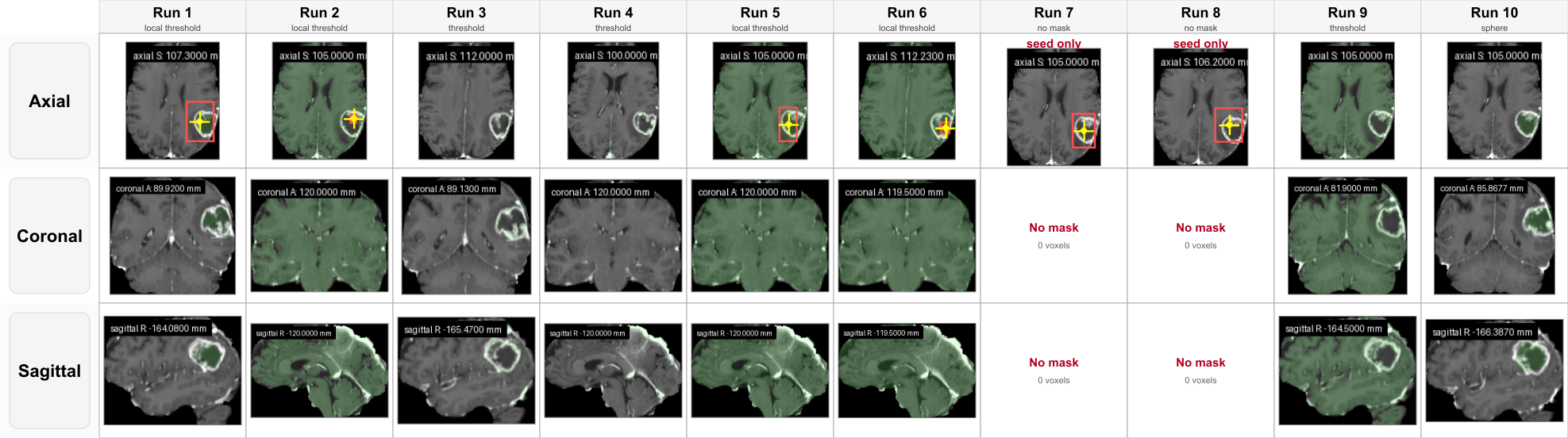
This figure is only used for segmentation failure analysis. It shows broad masks, local masks, seed-only evidence, and no-mask cases across repeated runs of the same task.
The first implementation keeps the release surface static: evaluation kit, data instructions, code links, and contact details can be filled as artifacts become public.
Canonical schemas, parsers, and scoring scripts.
Dataset licenses, preprocessing notes, and case packaging.
Track-specific result format and metadata requirements.
Prompt templates, runtime traces, and benchmark configuration.